macでPDFファイルからテキスト抽出しようとしてみた
暑いんだかちょうどいいんだか微妙な昼下がり。
「こんなページ作ってね。文章はこれで」と文書で手渡されたのはいいけど……かなりの長文。
その昔チャットで鍛えた(つもりの)タイピングを今こそ生かせ!って感じなのだけれど、何せ今日は暑いんだかちょうどいいんだか微妙な空気。
春の風に身をまかせ、時間ないのに悪あがきしてみました。
そうだPDFスキャンしてテキスト抽出しよう!
探ってみたら、このような素晴らしいページが。
そちらの説明によると……
MacでAutomatorを起動する
そんなアプリケーションがあったんだ……!
どれどれ
アイコンがなんかかわいい。
……で
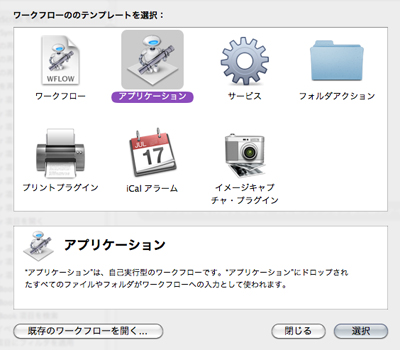
Automatorでアプリケーションを作成
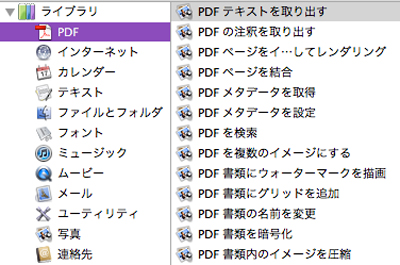
『ライブラリ』から『PDF』を選択し、『PDFテキストを取り出す』を右側にドラックする。
アプリケーションとして保存し、テキストを抽出したいPDFファイルをアプリケーションにドラッグ。
やった!と思いながら、わくわくして作成されたtxtファイルを、私のかわいいmiちゃんで開いてみると。

こんなはずじゃなかった……。
で、調べてみたら、そもそも最初から間違っていたことが判明。
スキャンする時に、OCR(文字認識処理)しなきゃいけなかったんですね。
最近のスキャナは便利になったな〜、とおばさん臭いことを考えながらリトライ。
ホッ。
……としたのもつかの間。
ふと思い立って、普通にAcrobat Readerで開いてみたら

最近のスキャナは便利になったな〜(涙目)
フタを開けてみれば、あんまり脳みそを使ってなかったNの、骨折り損のくたびれもうけでした。
それでもすごく勉強になったので感謝。活用します。
というか、2010年の記事なので、単にNが間抜けだっただけです。
参考先:Macの標準機能で、PDF書籍をテキストファイルに変換する
【ハートブレーン】https://blog.heart-kokoro.net/
【ハートブレーン】https://heartbrain.netよろしければ、SNSでのシェアやランキングなど、応援よろしくお願いします。

